Are large language models plagiarism machines, as some pending lawsuits allege?
Large language models, or LLMs, are the technology behind modern “generative AI” services like ChatGPT and Gemini.1 Their design mimics some aspects of how real brains absorb, encode, recall, and synthesize information. To the extent that that’s true, it’s hard to see how to call their output plagiarism — at least, not without also calling human writers plagiarists. Creativity is just combining sources, and it’s not plagiarism if you combine enough of them.
And yet, even if LLMs work exactly like human brains, there’s one thing they can do that humans can’t, and it means that the authors and artists currently suing OpenAI and Google and others do have a legitimate complaint, albeit a slightly different one than they think.
Join me on a discursive journey…
I’m thinking of a very popular English-language novel. It contains 122,368 words. Here is the beginning of its histogram: a list of the words in the novel, and how many times each one appears.
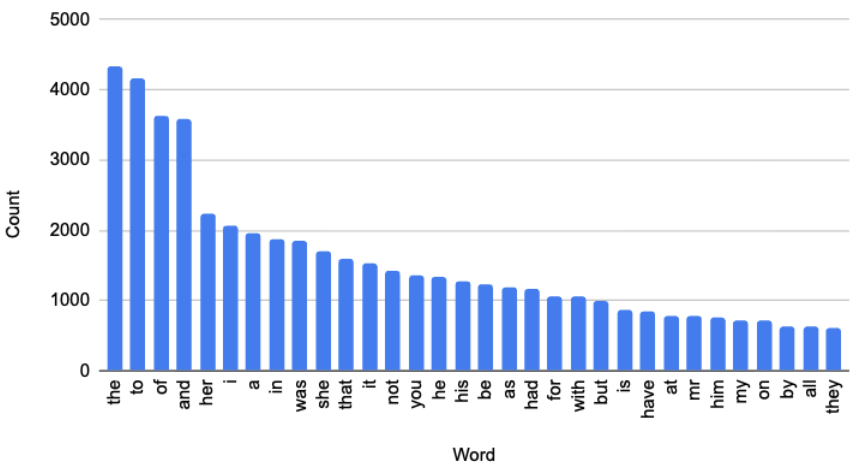
These are only the most-frequently occurring words in this novel. The full histogram, which you can see here, contains 6,343 entries, with some words used often (e.g. the 121 uses of “hope”) and some used seldom (e.g. the three uses of “shaken”). Add up all the uses of those 6,343 words and you get the aforementioned total of 122,368.
In giving you this information, have I plagiarized that novel? Clearly not. Although my histogram is derived from the novel, it is a total transformation of the information the novel contains. You can’t reconstruct the novel from my histogram2 or, in any meaningful way, get from my histogram what you can get from the novel.
Now suppose I add some information to the histogram. For each word, I tell you which words follow it, and how often. For example, “the” is followed by “whole” 72 times, “same” 69 times, “other” 58 times, “house” 56 times, and so on. We have “the envelope” and “the discussion” twice each, and “the prospects” once, among many other combinations. (In fact, there are 1,256 different words that follow “the” in this novel.) There are now two histograms: the first one, containing the count for each word; and a new one containing the count for each word pair.
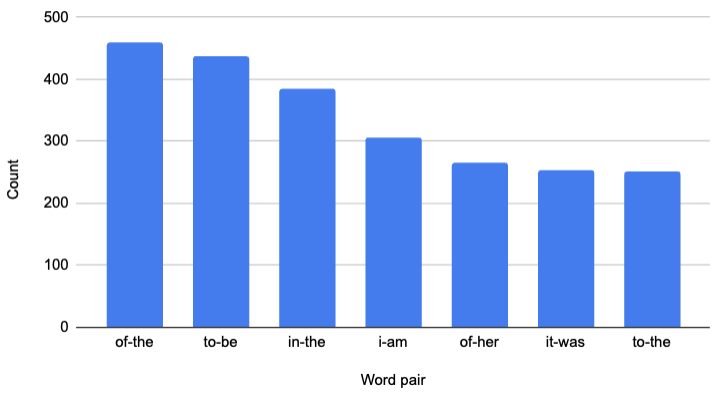
Have I plagiarized yet? It depends on how easily I’m able to reconstruct the novel, or substantial parts of it, from this enhanced information.
Here’s how I might try. First, I’d choose a starting word at random, based on the counts in the first histogram. That means it should be about twice as likely for me to choose “she” (1,709 occurrences) as it is for me to choose “is” (857). Imagine rolling a 122,368-sided die, with 4,334 sides labeled “the,” 4,166 sides labeled “to,” and so on.
Once I have my starting word, I repeatedly choose a next word based on the counts in the second histogram, the one containing word pairs. Here’s how that might go:
For my initial word, I choose “it” at random. The word “it” occurs 1,534 times out of 122,368 words, or 1.25% of the time.
The word-pairs histogram tells us that, of those 1,534 occurrences of “it,” the next word is “was” 254 times, “is” 193 times, “would” 69 times, and so on. I choose “is” at random, which follows “it” 12.6% of the time.
The pairs “is not” and “is a” occur 76 times each; “is the” occurs 36 times; “is very” occurs 34 times; and so on. I choose “a” at random (8.9%), and so far we have “It is a.”
There are 659 different words we could choose after “a,” from the likely — “very” — to the unlikely — “confession.” Suppose we land on an unlikely choice this time: “truth” (0.05%).
The word-pairs histogram guides us next to “universally” (3.7%) and “acknowledged” (33.3%) to give us one of the most famous opening phrases in English literature: “It is a truth universally acknowledged,” from Jane Austen’s Pride and Prejudice.3
To get even this far in reconstructing the input from the word and word-pairs histograms is enormously unlikely: 1.25%×12.6%×8.9%×0.05%×3.7%×33.3%, which is 0.000000086%. I’m much more likely to end up with some half-English, half-gibberish sequence like “It was to think so often meet.”4
Not to mention the fact that, character and place names aside, the vocabulary and phrasing in this novel is probably very close to that of Austen’s other novels. As unlikely as it is to reproduce Pride and Prejudice from this data, it’s probably about equally likely to produce something close to Sense and Sensibility.
The process I’ve just described is a simple example of a Markov-chain generator, which can read in some sample text and produce new text with some of the same statistical properties, like word and word-pair frequencies. You can make it fancier by considering word triples and quadruples, etc., in addition to single words and word pairs.
Large language models are far more complicated. But Markov chains are a good way to start thinking about how they work. In both cases, a data model is trained on some input text to produce a truckload of statistics. In both cases, those statistics are then used to generate some output text that tries to mimic the input text in some ways.
Let’s talk about brains for a moment — mine, specifically, since it’s the one about which I have the best information. Based on the evidence in front of you, you can tell my brain likes writing articles for public consumption from time to time. This began in college, when I became an avid fan of the prize-winning humorist Dave Barry, whose regular column in the Miami Herald was among the earliest syndicated content to be available on the ancient, text-only, pre-web Internet.
So inspired, I started contributing a weekly column of my own to my college newspaper. I cringe to think of those articles now. They were transparently striving to be Dave Barry articles, and reliably failing at that.
In large-language-model terms, my brain had been trained on too small a data set. Everything going into it was Dave-Barry-like, and so everything coming out of it was Dave-Barry-like too. Expecting anything else would be like trying to use my Jane Austen Markov-chain generator in the hope of producing something Hunter S. Thompson-like. It just wouldn’t work.
Time passed. I read a lot more and I wrote a lot more too. That Dave Barry training in my brain got blended with a few thousand more sources. It’s still in there, of course, but I think we can agree that it doesn’t make this article particularly Dave-Barry-like, any more than seasoning a curry with a pinch of cinnamon makes it taste cinnamony.
When I was writing my bad Dave Barry knockoff articles in college, was I plagiarizing him? No, I wasn’t. I wrote about my own topics. But they weren’t entirely original, either. They were a sort of mash-up of my topics with some of Dave Barry’s rhetorical patterns and joke-telling rhythms. I was appropriating his “voice.” (Trying, more like, with extremely limited success.)
I have long since found my own voice, but what does that mean, and when did it happen? The only possible answer is that my writing style — and by extrapolation, that of any writer — gradually became a mash-up of enough different ingredients, like the cinnamon in the curry, that no one of them is now particularly distinguishable. In other words, the difference between having an original voice and appropriating someone else’s is one of degree, not of kind. Nothing is truly, completely original — least of all this idea.
A human learns to write well by reading many authors. When we train an LLM by feeding it books, is that meaningfully different?
Some would say it is. “Machines can only mimic creativity,” they say.
I don’t know about that. I have firsthand experience with mimicking creativity, when I was in my Dave Barry phase. Turns out I just wasn’t trained enough yet. Now I am (I humbly suggest). No switch flipped. I didn’t go from “mimicking creativity” one day to “real creativity” the next. I just improved. As Voltaire said, creativity is mimicry, disguised.
Some would say, “computers have no awareness.” Do they not? How would we know? Do humans have awareness? How would we know that? The only available evidence — the written output — is comparably convincing in some cases and unconvincing in others, whether we’re talking about humans or computers.
I think we have to conclude that, until and unless we can demonstrate otherwise, the way an LLM learns and writes is at least in the same ballpark as the way a human brain does.
So if we accept that premise, are LLMs plagiarism machines?
The only possible answer is, in general, no — not any more than a human is. Plagiarism by computers and humans is certainly possible, when the mimicry isn’t sufficiently disguised beneath enough layers of influence — when there aren’t enough ingredients in the curry. But if anything, computers are probably less prone to this than humans, simply because of the sheer superhuman volume of sources on which they can be trained.
Generative AI companies are minting billions from LLM technology trained on the writings of many authors. Does this mean they owe those authors a cut?
Well, what do I owe Dave Barry for the contribution he made to my writing style? What do I owe to Jane Austen? To Carl Sagan? Neal Stephenson? Bill Bryson? Kurt Vonnegut? Stephen King? J.R.R. Tolkien? Ray Bradbury? Douglas Hofstadter? Roald Dahl? Edgar Allen Poe? Arthur Conan Doyle? Etc etc etc. They get no say in how I use the knowledge they helped me form, nor do they get to share in any benefits I enjoy from using that knowledge. I owe them only my gratitude, and the purchase price of their books, which I’ve already paid.
Assuming OpenAI and Google, et al., have paid that price for the sources used in their LLM training,5 and based on the conclusion that LLMs aren’t plagiarism machines, they shouldn’t owe authors and artists anything else.
Except…
Even if LLMs and human brains work similarly — even if it turns out they work identically — there is still one important difference between them: a trained LLM can be duplicated endlessly, and a brain cannot.
A single book sale can, in principle, “train” only a small number of human minds. But when it comes to LLMs, the same book can train hundreds, thousands, or millions of “individuals,” without bound, each one producing its own writing.
Existing copyright law rests invisibly on the assumption that getting a book’s contents into the heads of millions requires many, many copies of the book. It prohibits me from duplicating my copy and giving it to you — you’ve got to buy your own — but it doesn’t prohibit me from creating a functioning replica of the mind that resulted from reading that book, if only I could.
This insight suggests a way forward for the burgeoning LLM industry that might also be fair to the humans who supply them with their smarts, willingly or not: pay-per-mind. You bought a library full of books and trained an LLM with them? That’s fine. Now you want to spin up another copy of that same LLM? Pay a bit more to each copyright owner. How much? And how to track LLM individuals, and what they were trained on? I leave that to the legislators.
I am grateful to my sons for their feedback on an early draft of this essay.
- Generative AI encompasses a variety of different tools, some of which can produce pictures, or video, or music; some of which can interpret medical data and imagery; and so on. This essay focuses on written language and trusts that its observations can be extrapolated to other types of output. ↩︎
- In theory, since you have all the words and their counts, you could list them all and try shuffling them to put them in the right order. But the number of ways to permute 122,368 words is in excess of 8-with-569,426-zeroes-after-it — a number big enough to count every atom in our universe and another half-million universes just like it. So, good luck. ↩︎
- If I had included just one more bar in the “word-pair histogram” bar graph above, you would have seen that “mr-darcy” appears 243 times, which would have spoiled the surprise. ↩︎
- To get the rest of that famous opening sentence (“…that a single man in possession of a good fortune must be in want of a wife”) is many orders of magnitude unlikelier still. To say nothing of a paragraph, or a chapter, or the whole novel. ↩︎
- A safe assumption? I don’t know, and won’t comment. ↩︎